CPU软死锁问题分析¶
CPU软死锁现象¶
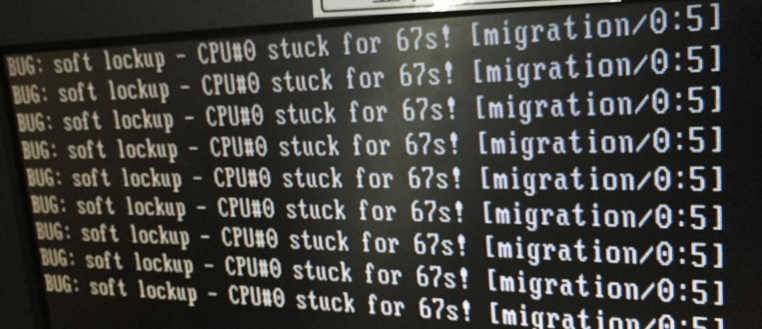
之前做服务器维护,经常遇到CPU软死锁的问题,如下图:
问题分析¶
CPU软死锁 kernel:BUG: soft lockup - CPU#0
上图报的问题是CPU0 出现的迁移进程(migration进程)软死锁,而系统的/var/log/messages又没有任何记录输出,那我们从migration进程开始分析:
------以下内容摘自网络------
linux多cpu负载平衡-线程迁移
move_tasks()在几个地方调用:
- load_balance()
- migrate_thread()---migration_thread
load balance在每个时钟节拍由 scheduler_tick()--->rebalance_tick()调用。 rebalance_tick开始在所有调度域上循环,其路径是从基本域(本地运行队列的sd字段)到最上层域。load_balance试图把本调度域中最繁忙的组的进程迁移到本地cpu上的运行队列。如果load_balance中的move_task调用失败,那么唤醒migration thread去沿着调度域的链搜索(从最忙运行队列的基本域到最上层)空闲cpu。
migration thread除了load_balance唤醒外, 在几种情况下调用:
- do_exec 系统调用, 寻找空闲cpu去加载新进程
- 改变cpu的亲和性affinity时
- migration_call(), 有cpu增减时
- 更新cpu domain时,(支持cpu热插拔)
- load_balance_newidle
------END------
由上述说明得出migration进程是做CPU负载均衡的一个任务迁移进程(多核CPU平均任务负载),为什么出现软死锁,我们在分析下Soft lockup:
Soft lockup名称解释:所谓,soft lockup就是说,这个bug没有让系统彻底死机,但是若干个进程(或者kernel thread)被锁死在了某个状态(一般在内核区域),很多情况下这个是由于内核锁的使用的问题。
Linux内核对于每一个cpu都有一个监控进程,在技术界这个叫做watchdog(看门狗)。通过ps –ef | grep watchdog能够看见
进程名称是watchdog/X(数字:cpu逻辑编号½/¾之类的)。像上边结果看出是个24线程的主机
这个进程或者线程每一秒钟运行一次,否则会睡眠和待机。这个进程运行会收集每一个cpu运行时使用数据的时间并且存放到属于每个cpu自己的内核数据结构。在内核中有很多特定的中断函数。这些中断函数会调用soft lockup计数,他会使用当前的时间戳与特定(对应的)cpu的内核数据结构中保存的时间对比,如果发现当前的时间戳比对应cpu保存的时间大于设定的阀值,他就假设监测进程或看门狗线程在一个相当可观的时间还没有执。
也就是说,migration进程太忙或者卡死,导致watchdog不及时,此时系统会打印CPU死锁信息:
| Bash | |
|---|---|
内核参数
kernel.watchdog_thresh(/proc/sys/kernel/watchdog_thresh)系统默认值为10。如果超过2*10秒会打印信息,注意:调整值时参数不能大于60。 虽然调整该值可以延长WatchDog等待时间,但是不能彻底解决问题,只能导致信息延迟打印。因此问题的解决,还是需要找到根本原因。 可以打开panic,将/proc/sys/kernel/panic的默认值0改为1,便于定位
为什么会导致migration进程太忙或者卡死,这时我想到了CPU 的 c-state技术
CPU 电源状态( C-States ):是一种基于Intel组件基础上的一项深度节能技术,这一技术在BIOS中可以设置使用或是不使用,此技术有独立的控制标准,具体的控制由BIOS来定,CPU在开启
C-State后,除了CPU自行省电以外,北桥与内存本身都会被CPU要求进入省电模式。
C-States从C0开始,C0是CPU的正常工作模式,CPU处于100%运行状态。C后的数越高,CPU睡眠得越深,CPU的功耗被降低得越多,同时需要更多的时间回到C0模式。
关于CPU c-state不同模式请参考: https://blog.csdn.net/foreverdengwei/article/details/6268543
http://blog.chinaunix.net/uid-25871104-id-3072582.html
我们的服务器采购后,都是采用默认BIOS设置,开启CPU节能模式,由此我分析是因为CPU设置了节能模式,致使CPU利用率不均衡,导致migration进程软死锁
解决办法¶
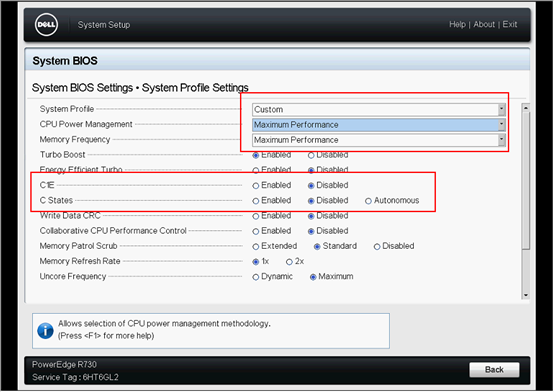
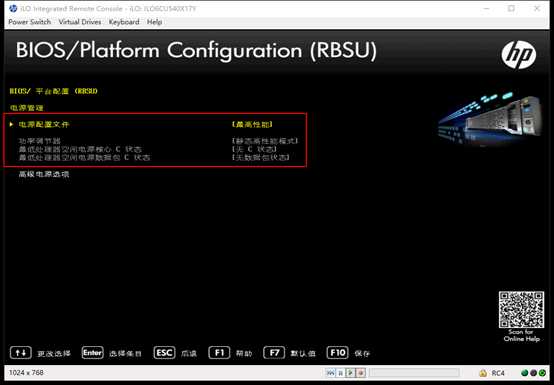
我们的服务器都是在机房托管使用,没有必要配置节能,最简单的处理方式是修改BISO,关闭C-states,将CPU、内存的电源功率调至最大,具体配置如下:
Dell
HP
关于软死锁的其他文档¶
软死锁不只是在显示屏上输出问题,在系统日志/var/log/messages也会有,大概如下:
| Bash | |
|---|---|
此处我只摘录了问题关键输出,在系统日志还有其他的提示,而且我没有遇到过,无法具体分析,但是可以看方括号后的进程与具体报错去分析问题
引发CPU死锁的原因有很多种,此处摘录几个网友的记录:
- 服务器电源供电不足,导致CPU电压不稳导致CPU死锁 https://ubuntuforums.org/showthread.php?t=2205211
- BIOS开启了超频,导致超频时电压不稳,容易出现CPU死锁 https://ubuntuforums.org/showthread.php?t=2205211
- vcpus超过物理cpu cores https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- 虚机所在的宿主机的CPU太忙或磁盘IO太高
- 虚机的的CPU太忙或磁盘IO太高 https://www.centos.org/forums/viewtopic.php?t=60087
- BIOS KVM开启以后的相关bug,关闭KVM可解决,但关闭以后物理机不支持虚拟化 https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
-
VM网卡驱动存在bug,处理高水位流量时存在bug导致CPU死锁
-
Linux kernel存在bug https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- KVM存在bug https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- clocksource tsc unstable on CentOS and cloud Linux with Hyper-V Virtualisation https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds 通过设置clocksource=jiffies可解决
- BIOS Intel C-State开启导致,关闭可解决 https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds https://support.citrix.com/article/CTX127395 http://blog.sina.com.cn/s/blog_906d892d0102vn26.html
- BIOS spread spectrum开启导致 当主板上的时钟震荡发生器工作时,脉冲的尖峰会产生emi(电磁干扰)。spread spectrum(频展)设定功能可以降低脉冲发生器所产生的电磁干扰,脉冲波的尖峰会衰减为较为平滑的曲线。 如果我们没有遇到电磁干扰问题,建议将此项设定为disabled,这栏可以优化系统的性能表现和稳定性; 否则应该将此项设定为enabled。 如果对cpu进行超频,必须将此项禁用。因为即使是微小的脉冲值漂移也会导致超频运行的cpu锁死。 再次强调:CPU超频时,SPREAD SPECTRUM必须关闭,否则容易出现锁死cpu的情况。