Dell 服务器磁盘故障处理
我们的服务器使用过程中,最常见的硬件故障就是磁盘,之前服务器都在保修期内时,发现故障直接报修厂商进行更换(热插拔,提前做好raid10),但是过保的服务器进行自己维修时,还是需要了解下具体的报错内容,方便定位问题,这就需要提前安装一些工具。
1、收集日志及故障分析
不仅出现硬盘故障需要收集日志,如果服务器其他问题,也需要收集日志,这里介绍三个工具DSET、TTY、MegaCli64
DSET工具
DSET日志是DELL机器报修时候,必要的日志,DSET可以收集所有硬件健康状态日志,还可以收集到硬件的部件号,售后可以根据部件号来确认故障配件是否属于本机原配,若不是原配配件,则需要另外提供采购的配件订单号,如果是过保的服务器,我们也可以使用此工具,收集日志自行查看
TTY工具
TTY日志是硬盘故障时,硬盘故障最怕的就是出现阵列穿孔,收集TTY日志,可以直观的看出阵列是否出现了穿孔(关键字:Puncturing bad block),自己可以收集TTY日志并查看
MegaCli64工具
接到服务器硬盘告警后要怎么做呢?当然是直接上服务器确认故障,使用MegaCli64工具可以查看磁盘状态 ,也可以查看raid其他信息及做些简单配置
2、公司现有Dell 服务器型号及RAID型号
服务器型号:
| Bash |
|---|
| PowerEdge R420
PowerEdge R710
PowerEdge R720
PowerEdge R730
PowerEdge R740
|
RAID卡型号:
| Bash |
|---|
| PERC 6/i Integrated
PERC H710P Mini
PERC H730P Mini
PERC H740P Adapter
|
以上型号是我们IDC目前大部分机型服务器,还有更早的11代 R410使用的SAS 6/iR 型号raid,需要安装DELL的srvadmin服务(不在本文档说明)
3、查看物理磁盘信息
| Bash |
|---|
| root@pts/0 # /opt/MegaRAID/MegaCli/MegaCli64 -Pdlist -a0
|
执行上边命令得出下方磁盘信息,这里只截取了第一块磁盘的信息,其他磁盘信息一样,大家要记住第一行 Adapter #0,表示有0个适配器,MegaCli64很多命令都要在最后用-a指定Adapter,我只有Adapter #0 所以今后都写-a0就行,还可以-a0,1,2或-aALL
| Bash |
|---|
| Adapter #0
Enclosure Device ID: 32
Slot Number: 0
Drive's postion: DiskGroup: 1, Span: 0, Arm: 0
Enclosure position: 0
Device Id: 0
WWN: 50000396F8282E6C
Sequence Number: 2
Media Error Count: 0
Other Error Count: 0
Predictive Failure Count: 0
Last Predictive Failure Event Seq Number: 0
PD Type: SAS
Raw Size: 5.458 TB [0x2baa0f4b0 Sectors]
Non Coerced Size: 5.457 TB [0x2ba90f4b0 Sectors]
Coerced Size: 5.457 TB [0x2ba900000 Sectors]
Firmware state: Online, Spun Up
Device Firmware Level: DR06
Shield Counter: 0
Successful diagnostics completion on : N/A
SAS Address(0): 0x50000396f8282e6e
SAS Address(1): 0x0
Connected Port Number: 0(path0)
Inquiry Data: TO***BA MG*******EE DR************GC
FDE Enable: Disable
Secured: Unsecured
Locked: Unlocked
Needs EKM Attention: No
Foreign State: None
Device Speed: 12.0Gb/s
Link Speed: 12.0Gb/s
Media Type: Hard Disk Device
Drive Temperature :27C (80.60 F)
PI Eligibility: Yes
Number of bytes of user data in LBA: 512
Drive is formatted for PI information: Yes
PI: PI with type 2
Drive's write cache : Disabled
Port-0 :
Port status: Active
Port's Linkspeed: 12.0Gb/s
Port-1 :
Port status: Active
Port's Linkspeed: 12.0Gb/s
Drive has flagged a S.M.A.R.T alert : No
|
这里会获取到很多信息,重点了解如下几个参数:
| Bash |
|---|
| Adapter #0: 适配器个数,从0起
Slot Number: 服务器硬盘插槽号,从0开始,跟机器外观上的标识一致。如果故障,直接告诉现场工程师slot X的硬盘有问题,工程师就会直接换盘
Media Error Count: 硬盘物理错误数
Other Error Count: 硬盘逻辑错误数
Predictive Failure Count: 预告警数
Last Predictive Failure Event Seq Numbe: 最后一个预测失败事件的编号
PD Type: 磁盘类型(SAS,STAT)
Raw Size: 磁盘容量
Firmware state: 硬盘状态
Inquiry Data: 磁盘的序列号,跟磁盘标签上一致。磁盘标签需要拔盘才能看到
|
3.1、磁盘报错关注的参数
| Bash |
|---|
| Firmware state: Online, Spun Up
|
这个参数可以看到磁盘的状态,Online是我们期望看到的最好状态,除此之外还有 Unconfigured Offline Failed等等,大多表达一个悲伤的事实:你要加班报修/修复他们了。。。
关于Firmware state参数的几个状态解释:
| Bash |
|---|
| Online, Spun Up #硬盘在线,正在使用
Rebuild #更换硬盘后,正在重建
Failed #硬盘故障了,直接更换
Unconfigured(bad), Spun Up #硬盘还未配置,但是故障了,直接更换
Unconfigured(good), Spun Up #硬盘还未配置,可以使用,需要时可以再raid配置页面配置
JBOD, Spun Up #硬盘使用non-Raid模式
Hotspare , Spun Up #硬盘做热备使用
CopyBack #硬盘回写状态,这个在有热备盘的情况下才会出现,当有热备盘的阵列中,出现有一块硬盘出现故障,则热备盘会直接进入rebuiled状态,重建完成后,阵列状态就会恢复正常,这个时候,我们如果把故障硬盘替换掉,在有开启copyback模式的服务器上,这块刚刚替换上的新盘就会被标记为copyback状态,会将原来的热备盘的数据,全部回写到新盘上,而原来的热备盘,会重新变为热备
|
还有一个==Offline==的状态,此状态在系统一般看不到,用MegaCli64工具查看也都正常。但是会在RAID配置界面看到磁盘是属于掉线状态,可以再配置界面按需import,我们加监控不只需要查看磁盘状态,也需要检查磁盘个数与原始数量是否一致,避免有掉线查看不到的情况
也可以在机房巡检时查看,Dell服务器硬盘架上会有上下两个指示灯,正常为绿色、故障为黄色,黄绿交替闪烁表示磁盘有预告警,需要注意,及时更换,如果上边指示灯不亮,下边亮,即说明磁盘不在线
3.2、需要特别关注这几个指标
| Bash |
|---|
| Media Error Count
Other Error Count
Predictive Failure Count
Last Predictive Failure Event Seq Number
|
这四个参数都有可能不是0。这意味着磁盘虽然能用但已经不再可靠,很有可能存在坏簇、坏道之类的问题,必须尽快换掉这块盘。如果坚持使用,那磁盘就离彻底坏掉不远了。网上流传的说法是前3个Count越大代表磁盘状态越差,实际并不是这样,以下2个截图就可以说明。
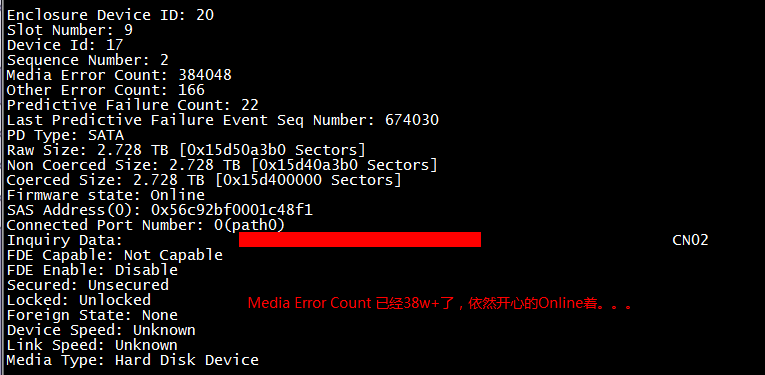
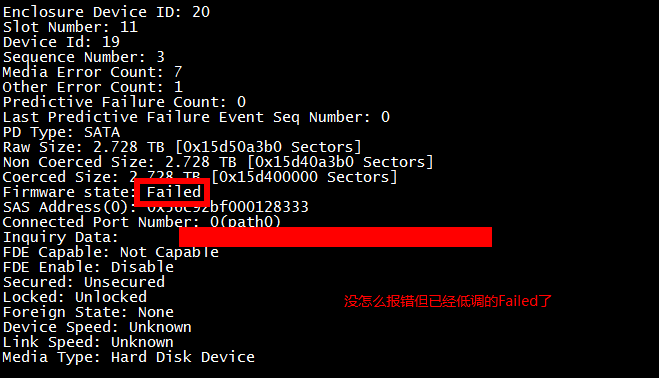
这个问题专门与服务器RAID卡磁盘厂家沟通,得到的反馈是:
Media error、other error数值的绝对值,不能直接反应硬盘的状态。
根据与RAID卡、硬盘厂家的沟通,建议做法是监控Predictive Failure 的数值,不为零说明硬盘有问题。Predictive Failure中已经涵盖media error,而且比media error的范围更广、更全面。
硬盘的 SMART 子系统已经具备一套完整的算法来评估硬盘的健康状况,SMART 子系统算法会参考硬盘运行时各个方面的参数,media error 是其中一项,SMART 对于 media error 的评估是基于单位时间增长数来计算的,当 SMART 子系统中任何一个评估项达到对应的阈值时,硬盘会报告 Sense Code: 01 5D 00 (FAILURE PREDICTION THRESHOLD EXCEEDED),遵循 SCSI 协议标准的 host (OS SCSI 子系统,SAS 控制器, RAID 卡等) 可以正确解析出该 Sense Code。
综上,由于 media error 已经被硬盘 SMART 子系统所涵盖,并且会依据 SCSI 协议标准上报 predictive failure,所以硬盘部分只需要在Raid卡下关注Predictive Failure就好,标准为不能大于0
4、查看物理磁盘Raid信息
| Bash |
|---|
| root@pts/21 # /opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -aALL
|
为了更好的说明raid信息,我在Dell PowerEdge R730xd 上执行上述命令,R730xd服务器是前置12块6T的存储盘,后置两块300G的系统盘,显示如下:
| Bash |
|---|
| Adapter 0 -- Virtual Drive Information:
Virtual Drive: 0 (Target Id: 0)
Name :
RAID Level : Primary-1, Secondary-0, RAID Level Qualifier-0
Size : 278.875 GB
Mirror Data : 278.875 GB
State : Optimal
Strip Size : 64 KB
Number Of Drives : 2
Span Depth : 1
Default Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU
Current Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU
Default Access Policy: Read/Write
Current Access Policy: Read/Write
Disk Cache Policy : Disk's Default
Encryption Type : None
Default Power Savings Policy: Controller Defined
Current Power Savings Policy: None
Can spin up in 1 minute: Yes
LD has drives that support T10 power conditions: Yes
LD's IO profile supports MAX power savings with cached writes: No
Bad Blocks Exist: No
PI type: No PI
Is VD Cached: No
Virtual Drive: 1 (Target Id: 1)
Name :
RAID Level : Primary-6, Secondary-0, RAID Level Qualifier-3
Size : 54.575 TB
Parity Size : 10.915 TB
State : Optimal
Strip Size : 64 KB
Number Of Drives : 12
Span Depth : 1
Default Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU
Current Cache Policy: WriteBack, ReadAhead, Direct, No Write Cache if Bad BBU
Default Access Policy: Read/Write
Current Access Policy: Read/Write
Disk Cache Policy : Disk's Default
Encryption Type : None
Default Power Savings Policy: Controller Defined
Current Power Savings Policy: None
Can spin up in 1 minute: Yes
LD has drives that support T10 power conditions: Yes
LD's IO profile supports MAX power savings with cached writes: No
Bad Blocks Exist: No
PI type: No PI
Is VD Cached: No
Exit Code: 0x00
|
以上配置显示我们做了两个raid,第一个raid1,是系统盘,第二个raid6是做存储使用
常用参数解释:
| Bash |
|---|
| Virtual Drive: 虚拟驱动器号,也就是raid组号
Name: Raid组名字,主要为了便于管理,我们都没有特意指定
RAID Level: Raid级别
Size: 做完raid后的硬盘大小
Mirror Data: 镜像大小
Parity Size: 奇偶校验大小
State: RAID状态
Strip Size: Strip是在每个磁盘上预先定义好的一定数量的连续的Block;Strip Size指的是一个strip中的最大数据大小即block number* block size
Number Of Drives: 每个Raid组里硬盘个数
|
以上其他参数比较好理解,这里稍微引入下RAID中用到的3个主要技术:Striping、Mirroring、Parity
| Bash |
|---|
| Striping(条带化):就是将一块连续的数据分成很多小部分并把他们并行的存储到不同磁盘上去。其中涉及到几个术语 Strip,Stripe,Strip size,Stripe size。Strip就是在每个磁盘上预先定义好的一定数量的连续的Block。在RAID中所有磁盘上的Strip一起叫做一个Stripe。Strip size (Stripe depth)指的是一个strip中的最大数据大小即block number* block size。Stripe size指的就是stripe的大小即disk number * strip size。
Mirroring (镜像):就是将同一数据存储在两块不同的硬盘上,从而产生该数据的两个copy。当其中一块faulted,替换了新disk之后,Controller会自动将好的磁盘中的数据copy到新的磁盘中。
Parity(奇偶校验):主要是来为Striped RAID提供数据保护功能。利用位异或(XOR)的算法,将产生的校验值额外进行保存在磁盘上。可以是额外的一块磁盘,也可以分布在所有磁盘上,Parity Size:10.915 TB 这是将校验数据存储在两个6T磁盘上了。
|
4.1、常见RAID
我们机房服务器主要用到RAID0、RAID1、RAID10、RAID5、RAID6,也是比较常见的RAID配置,关于RAID详细技术,请参考其它文档,这里主要介绍下我们关注的问题:
| Bash |
|---|
| Primary-0, Secondary-0, RAID Level Qualifier-0 :RAID 0
Primary-1, Secondary-0, RAID Level Qualifier-0 : RAID 1
Primary-1, Secondary-3, RAID Level Qualifier-0 :RAID 10
Primary-5, Secondary-0, RAID Level Qualifier-3 :RAID 5
Primary-6, Secondary-0, RAID Level Qualifier-3 :RAID 6
|
这里说明下,一般RAID卡自带RAID10的配置参数,直接配置的话,RAID10 也会显示为Primary-1, Secondary-0, RAID Level Qualifier-0 ,可以查看Number Of Drives 磁盘个数判断,大于2块的偶数就是RAID10
4.2、RAID故障分析
RAID状态
| Bash |
|---|
| State: Optimal #阵列正常
State: Degraded #阵列降级
|
State: Optima
并不是Optimal状态下,就说明该机器上就没有磁盘故障了,因为有的机器有热备盘,硬盘故障后,热备盘会直接进入rebulid状态(重建状态中,RAID等级是Degraded),rebulid完成后,RAID状态恢复正常,但是物理磁盘还会有故障提示,此时就要处理物理磁盘
State: Degraded
阵列进入降级状态,就能直接处理硬盘了吗?当然不是,还需要确认RAID等级,当RAID进入降级状态,不同的RAID等级下我们会有不同的处理方式,这个是根据RAID级别算法来定的
| Bash |
|---|
| RAID 0 :硬盘挂1块,就真的挂了,我们机房都是以机器为数据冗余,大家使用要注意数据备份,别追悔莫及
RAID 1 :允许坏1块,记得及时更换
RAID 10 :最多允许N/2块硬盘故障,但是前提是这N/2块故障盘必须是分布在不同的raid1上的
RAID 5 :最多允许1块硬盘故障,当然如果你的机器中有热备盘的话,最多可以允许热备盘数量+1块盘故障
RAID 6 :最多允许坏2块
|
5、总结
通过故障分析,我们知道了具体故障的磁盘,可以查到在哪个机房、哪个机架、哪台服务器,但还是不能直接更换,因为什么呢?通过多年采坑经验,任何一个操作,都是有风险的,很有可能造成整个设备宕机,甚至数据丢失,即使我们做了RAID10;
近期一个真实例子,更换前端redis服务器硬盘,其中1块硬盘故障后,替换新的硬盘,查看状态是rebuilding,没过几分钟,整个系统故障,显示 input/output error,系统只读了;
原因是替换了新的磁盘后,会由同raid组的另一块磁盘同步数据,此时整块磁盘会大量读写,而我们的设备已服役6年以上,扛不住突然增大的压力,另一块磁盘也直接挂掉了,好在我们踩过的坑多了,已经提前将担任redis master节点切换到slave上了,才没有对业务造成影响(心存敬畏吧!),最后只能重装了系统~
所以,我们在机房设备操作之前,一定要确保数据备份,业务可以容忍宕机的情况下,安全维护!!!
注意:更换硬盘不只是要查看硬盘容量、位置,还要确认好型号、尺寸、速率、转速等参数